
DSL查询语言
DSL简介
DSL(Domain Specific Language)是一种专门为某一领域设计的语言,它是一种用来与特定领域的专家进行沟通的语言,它是一种抽象的语言,它是一种用来描述某一领域的语言。DSL的目的是为了简化复杂的查询,使得查询更加简单、易于理解。
Elasticsearch提供了丰富的DSL,包括查询语言、过滤语言、聚合语言、排序语言、脚本语言等。这些DSL可以帮助用户快速、高效地查询、过滤、聚合、排序数据。
DSL的语法与Elasticsearch的RESTful API相似,但有一些差异。DSL的语法更加简洁、易于理解,并且支持更丰富的查询功能。
ES的两种查询方式
Elasticsearch提供了两种查询方式:
- 基于RESTful API的查询方式
GET /user/_search?q=name:张三说明:这种查询方式使用HTTP协议的GET方法,通过URL参数的方式指定查询条件。 查询的是索引user,查询条件是name为张三。
- 基于DSL的查询方式 Elasticsearch提供丰富且灵活的查询语言叫做DSL查询(Query DSL),它允许你构建更加复杂、强大的查询。 DSL(Domain Specific Language特定领域语言)以JSON请求体的形式出现。
POST /user/_search
{
"query": { # 查询条件
"match": { # 匹配查询
"name": "张三" # 字段名和查询值
}
}
}平时更多采用这种方式,因为可操作性更强,处理复杂请求时更得心应手。
全文检索
match_all查询
一般生产环境下不会这么做,因为数据量有可能非常大,所以查询非常耗时,因此一般用于测试用。
match_all查询会匹配所有文档,它的查询条件是match_all,语法如下:
GET /indexName/_search
{
"query": {
"match_all": {} // 由于这里是查询所有数据,因此没有查询条件
}
}match查询
match查询是最常用的查询,它可以用于全文检索。match查询会对查询条件进行分词,然后进行匹配。
match:根据一个字段查询
语法:
GET /indexName/_search
{
"query": {
"match": {
"FIELD": "TEXT"
}
}
}相关信息
- FIELD:字段名
- TEXT:查询条件
- match查询会对查询条件进行分词,默认分词器是standard,可以自定义分词器。相应字段中分词后有满足的即可命中
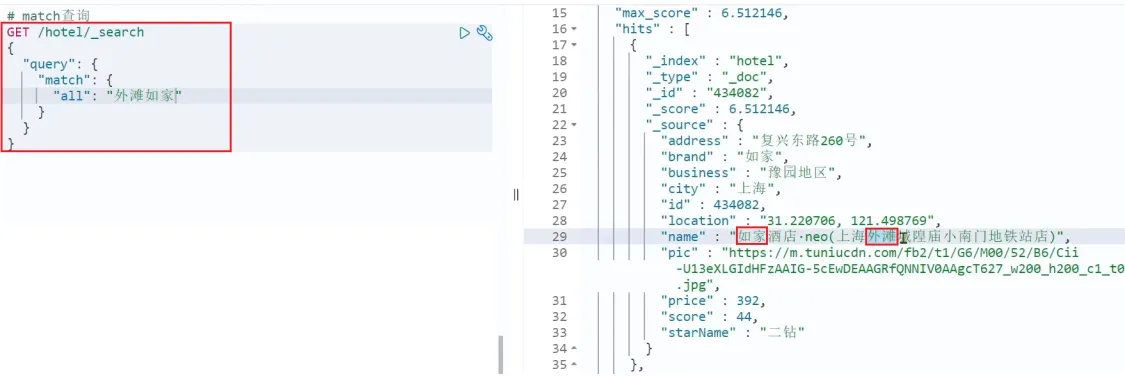
GET /user/_search
{
"query": {
"match": {
"remark": {
"query": "中国",
"analyzer": "ik_smart" # 指定分词器
}
}
}
}
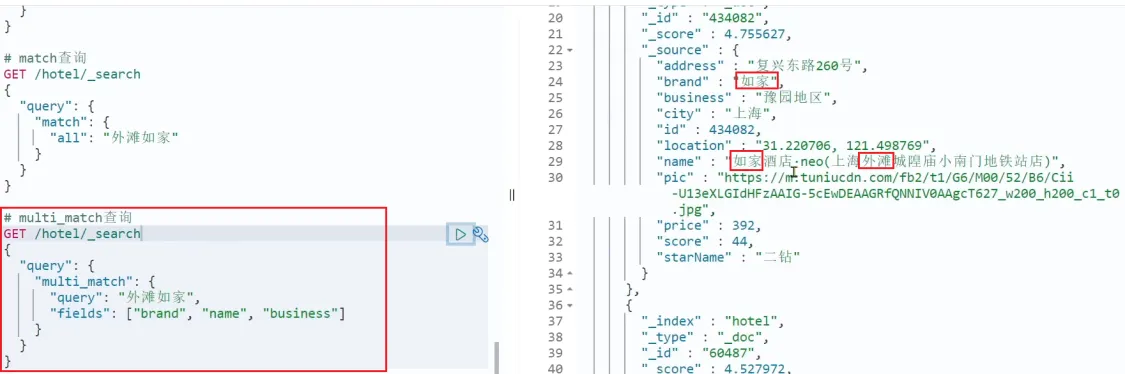
multi_match查询
multi_match查询可以同时对多个字段进行全文检索(任意一个字段符合条件就算符合查询条件)。它会对查询条件进行分词,然后进行匹配。
根据多个字段查询,参与查询字段越多,查询性能越差。【推荐:使用copy_to构造all字段】
语法:
GET /indexName/_search
{
"query": {
"multi_match": {
"query": "TEXT",
"fields": ["FIELD1", "FIELD2"]
}
}
}
match_phrase查询
match_phrase查询可以用于短语查询。
语法:
GET /indexName/_search
{
"query": {
"match_phrase": {
"FIELD": "TEXT"
}
}
}
案例:
```json
GET /test1/_search
{
"query": {
"match_phrase": {
"address": {
"query": "中国"
}
}
}
}相关信息
- match_phrase查询会对查询条件进行分词,并且按照正确的顺序出现。也就是说,它不仅检查词语的存在性,还检查它们的位置关系。
- 可以使用slop参数控制匹配的位置关系。slop参数指定了词语之间的最大距离。
GET /user/_search
{
"query": {
"match_phrase": {
"reamrk": {
"query": "是中国人",
"slop": 1 # 最大允许词语间隔
}
}
}
}match_phrase_prefix查询
match_phrase_prefix查询可以用于短语前缀查询。智能搜索--以什么开头。
语法:
GET /indexName/_search
{
"query": {
"match_phrase_prefix": {
"FIELD": "TEXT"
}
}
}案例:
GET /test1/_search
{
"query": {
"match_phrase_prefix": {
"remark": "印度"
}
}
}相关信息
- match_phrase_prefix查询类似于match_phrase查询,但它允许最后一个词作为一个前缀来匹配。换句话说,它可以看作是一个自 动完成或即时搜索功能,其中用户输入的部分字符串被视为完整单词的开始。
- 例如,如果搜索“quick br”,match_phrase_prefix将会寻找以“br”开头的所有单词,并且这些单词需要紧跟在“quick”之后。所 以它可能会匹配到“quick brown”。
- 此查询非常适合于实现搜索建议或自动完成功能。
精确查询
term查询
term查询是最基本的查询,它可以用于精确匹配某个字段的值。 term查询不会分析查询条件(不会对条件分词),只有当词条和查询字符串完全匹配时才匹配,也就是精确查找,比如数字,日期,布尔值或 not_analyzed 的字符串(未经分词数据类型):
{
"term": {
"field": "value"
}
}案例:
当我搜索的是精确词条时,能正确查询出结果: 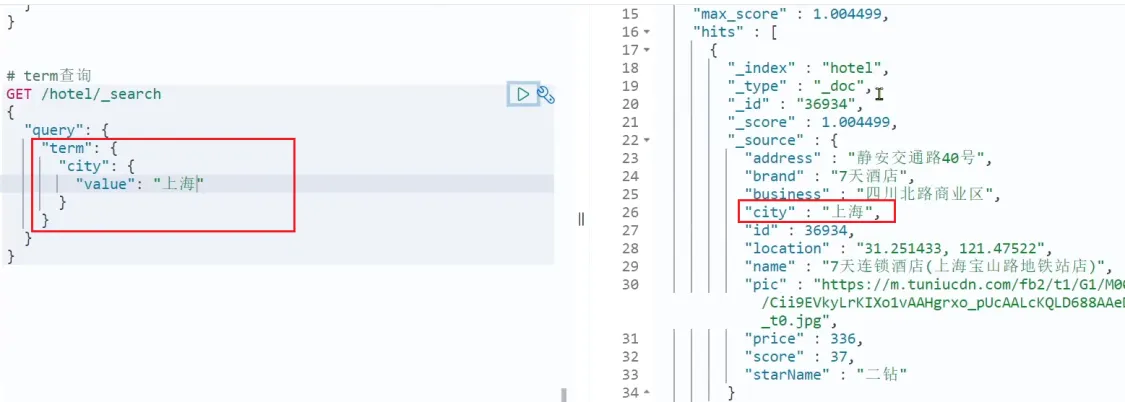 但是,当我搜索的内容不是词条,而是多个词语形成的短语时,反而搜索不到:
但是,当我搜索的内容不是词条,而是多个词语形成的短语时,反而搜索不到: 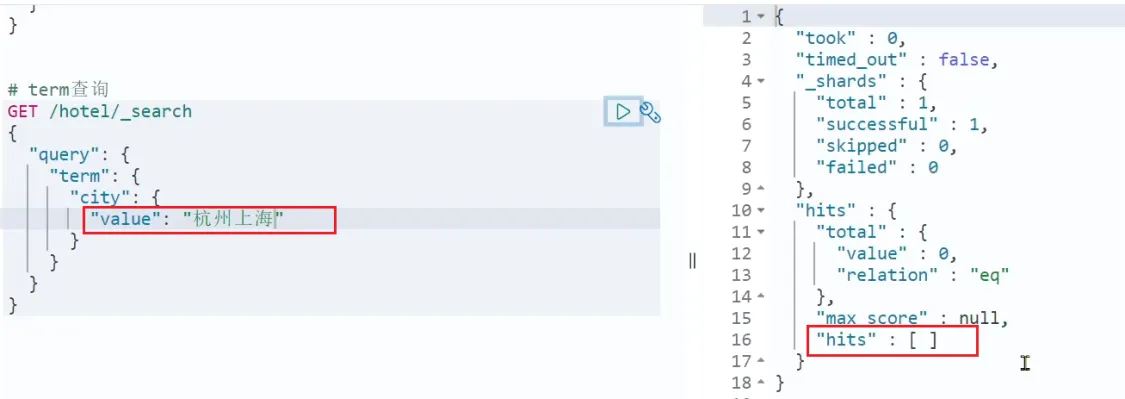
terms查询
terms查询多个精确匹配的词条。 term 查询对于查找单个值非常有用,但通常我们可能想搜索多个值。 如果我们想要查找价格字段值为 $20 或 $30 的文档该如何处理呢? 这时,我们可以使用 terms 查询:
语法:
GET /indexName/_search
{
"query": {
"terms": {
"FIELD": ["VALUE1", "VALUE2"]
}
}
}range查询
范围查询,一般应用在对数值类型做范围过滤的时候。比如做价格范围过滤。
语法:
GET /indexName/_search
{
"query": {
"range": {
"FIELD": {
"GT": VALUE1,
"LT": VALUE2
}
}
}
}相关信息
- GT: greater than,大于
- LT: less than,小于
- GTE: greater than or equal,大于等于
- LTE: less than or equal,小于等于
案例: 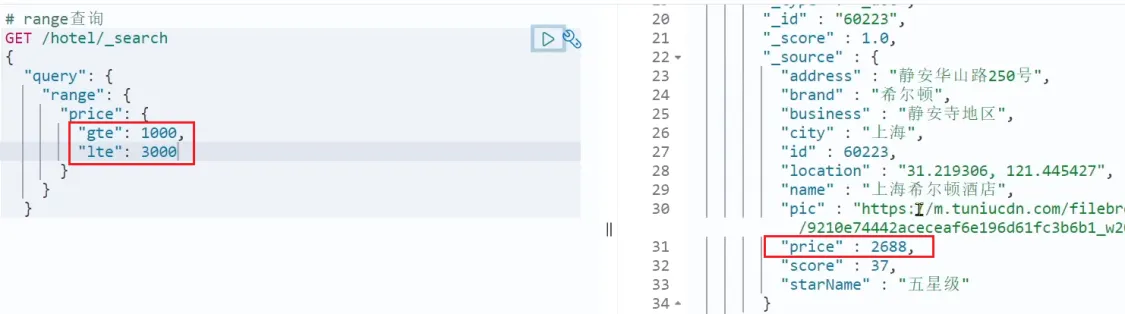
ids查询
ids查询可以根据文档的id精确查询。
GET /indexName/_search
{
"query": {
"ids": {
"values": ["ID1", "ID2"]
}
}
}案例:
GET hotel/_search
{
"query": {
"ids": {
"values": ["36934","38665"]
}
}
}通配符查询(wildcard)
wildcard查询:会对查询条件进行分词。还可以使用通配符 ?(任意单个字符) 和 * (0个或多个字符)
语法:
GET /indexName/_search
{
"query": {
"wildcard": {
"FIELD": {
"VALUE": "PATTERN"
}
}
}
}案例:
GET /test1/_search
{
"query": {
"wildcard": {
"name": {
"value": "李*"
}
}
}
}查询name字段中李开头的
复合查询
布尔查询(bool)
布尔查询可以组合多个查询条件,并对其进行逻辑组合。 bool查询可以包含多个子查询,每个子查询可以是布尔查询,也可以是其他查询。
子查询的组合方式有:
- must:必须匹配每个子查询,类似“与”
- should:选择性匹配子查询,类似“或”
- must_not:必须不匹配,不参与算分,类似“非”
- filter:过滤满足条件的数据 注意:尽量在筛选的时候多使用不参与算分的must_not和filter,以保证性能良好
语法:
GET /indexName/_search
{
"query": {
"bool": {
"must": [ // 必须匹配 and
{
"match": {
"FIELD1": "TEXT1"
}
},
{
"match": {
"FIELD2": "TEXT2"
}
}
],
"should": [ // 选择性匹配 or
{
"match": {
"FIELD3": "TEXT3"
}
},
{
"match": {
"FIELD4": "TEXT4"
}
}
],
"must_not": [ // 必须不匹配 not
{
"match": {
"FIELD5": "TEXT5"
}
}
],
"filter": [ // 条件过滤查询
{
"range": {
"FIELD6": {
"GT": VALUE1,
"LT": VALUE2
}
}
}
]
}
}
}must
多个查询条件必须完全匹配,相当于关系型数据库中的 and。如果有一个条件不满足则不返回数据。
案例:
GET /test1/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"name": "张三"
}
},
{
"match": {
"age": "25"
}
}
]
}
}
}查询的结果中必须包含name为张三,age为25的文档。
should
多个查询条件只要满足一个即可,相当于关系型数据库中的 or。
案例:
GET /test1/_search
{
"query": {
"bool": {
"should": [
{
"match": {
"name": "张三"
}
},
{
"match": {
"age": "25"
}
}
]
}
}
}查询的结果中只要包含name为张三或age为25的文档。
must_not
查询条件必须不匹配,相当于关系型数据库中的 not。
案例:
GET /test1/_search
{
"query": {
"bool": {
"must_not": [
{
"match": {
"name": "李四"
}
},
{
"match": {
"age": 30
}
}
]
}
}
}查询的结果:name不是李四并且年龄不是30的文档信息
filter
查询条件必须满足,但不参与计算分值,相当于关系型数据库中的 where。filter查询可以用于过滤数据,比如只显示满足条件的数据,而不显示不满足条件的数据。
案例:
GET /test1/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"name": "李四"
}
}
],
"filter": {
"range": {
"age": {
"gte": 20,
"lt": 30
}
}
}
}
}
}查询出用户年龄在20-30岁之间名称为 李四 的用户
设置查询结果
查询结果字段过滤
我们在查询数据的时候,返回的结果中,所有字段都给我们返回了,但是有时候我们并不需要那么多,所以可以对结果进行过滤处理。
语法:
GET /indexName/_search
{
"query": {
"match_all": {}
},
"_source": ["FIELD1", "FIELD2"] // 只返回指定字段
}排序
排序可以对查询结果进行排序,Elasticsearch支持多种排序方式,在使用排序后就不会进行算分了。
- 普通字段排序
排序条件是一个数组,也就是可以写多个排序条件。按照声明的顺序,当第一个条件相等时,再按照第二个条件排序,以此类推
语法:案例:GET /indexName/_search { "query": { "match_all": {} }, "sort": [ { "FIELD1": { "order": "DESC" // 降序 } }, { "FIELD2": { "order": "ASC" // 升序 } } ] }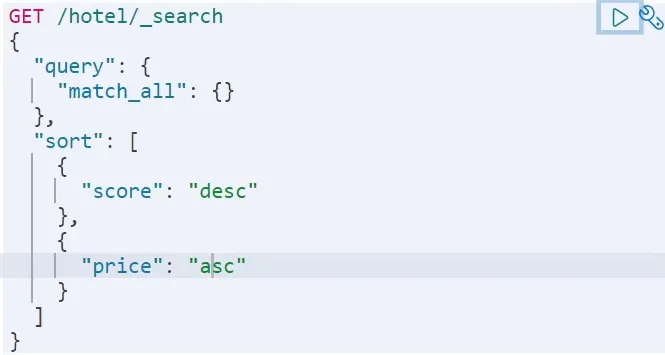
- 地理坐标排序
语法:
GET /indexName/_search
{
"query": {
"match_all": {}
},
"sort": [
{
"_geo_distance": {
"location": [13.404954, 52.520008], // 经纬度
"order": "asc",
"unit": "km" // 单位
}
}
]
}相关信息
这个查询的含义是:
- 指定一个坐标,作为目标点
- 计算每一个文档中,指定字段(必须是geo_point类型)的坐标 到目标点的距离是多少
- 根据距离排序,距离越近的文档排在前面
案例:
需求描述:实现对酒店数据按照到你的位置坐标的距离升序排序
提示:获取你的位置的经纬度的方式:获取经纬度
假设我的位置是:31.034661,121.612282,寻找我周围距离最近的酒店。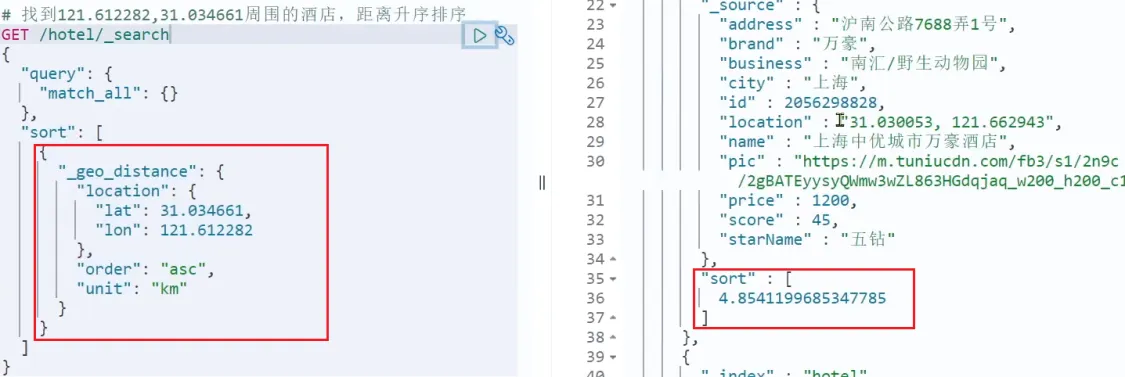
分页
分页可以对查询结果进行分页,Elasticsearch默认每页显示10条数据,可以通过from和size参数进行分页。 语法:
GET /indexName/_search
{
"query": {
"match_all": {}
},
"from": 0, // 跳过的文档数量,从0开始查询
"size": 10 // 每页显示的文档数量
}高亮
注意:
- 高亮是对关键字高亮,因此搜索条件必须带有关键字,而不能是范围这样的查询。
- 默认情况下,高亮的字段,必须与搜索指定的字段一致,否则无法高亮
- 如果要对非搜索字段高亮,则需要添加一个属性:required_field_match=false
使用场景:在百度等搜索后,会对结果中出现搜索字段的部分进行高亮处理。 语法:
GET /hotel/_search
{
"query": {
"match": {
"FIELD": "TEXT" // 查询条件,高亮一定要使用全文检索查询
}
},
"highlight": {
"fields": { // 指定要高亮的字段
"FIELD": { //【要和上面的查询字段FIELD一致】
"pre_tags": "<em>", // 用来标记高亮字段的前置标签
"post_tags": "</em>" // 用来标记高亮字段的后置标签
}
}
}
}案例:组合字段all的案例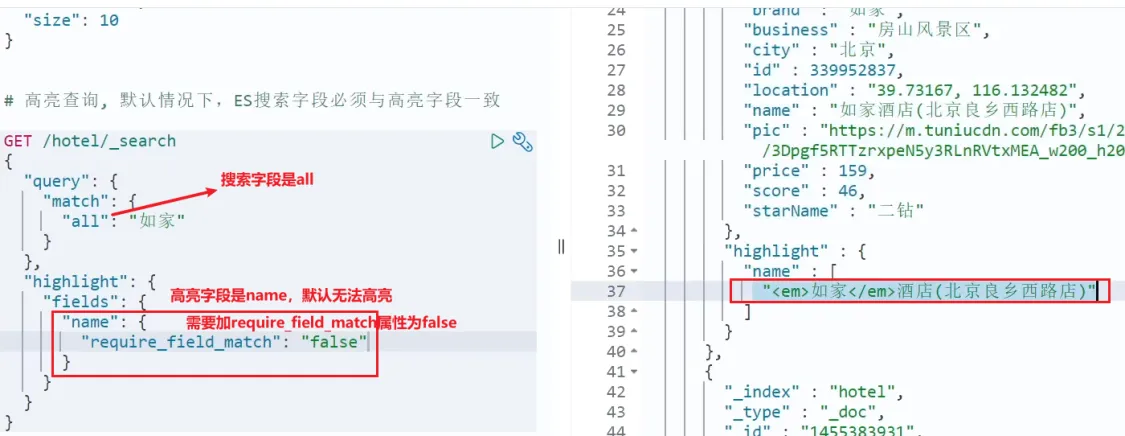
聚合
概念及分类
在Elasticsearch中,聚合查询(Aggregations)是一种用于对搜索结果进行统计分析的强大工具。它允许用户基于搜索的数据提取更高级的信息和洞察,而不仅仅是检索文档。聚合可以非常简单,也可以相当复杂。
聚合的常见种类:
- 桶(Bucket)聚合:将数据分成一组固定大小的桶(分组查询),并对桶中的数据进行聚合操作。
- 度量(Metric)聚合:对数据进行度量统计,如求和(sum)、平均值(avg)、最大值(max)、最小值(min)等。
- 管道(Pipeline)聚合:其它聚合的结果为基础做聚合如:用桶聚合实现种类排序,然后使用度量聚合实现各个桶的最大值、最小值、平均值等。
桶聚合
桶聚合是最常见的聚合,它可以将数据分成一组固定大小的桶,并对桶中的数据进行聚合操作。
语法:
GET /indexName/_search
{
"query": { // 限定聚合的数据范围
"match_all": {}
},
"aggs": {
"NAME": { // 聚合名称
"TYPE": { // 聚合类型
"FIELD": "VALUE" // 聚合字段
}
}
}
}相关信息
聚合三要素:
- NAME:聚合名称,自定义,用于区分不同的聚合
- TYPE:聚合类型,包括term, terms、date_histogram、range等
- FIELD:聚合字段,根据聚合类型不同,字段类型也不同
配合聚合的属性有:
- size:terms聚合的桶大小
- order:terms聚合的排序方式
- field: 指定聚合的字段
案例:对酒店品牌进行聚合查询。(对酒店品牌进行分组,统计每个品牌的数量)
GET /hotel/_search
{
"size": 0, // 不显示查询结果,只显示聚合结果
"query": { //限定聚合的数据范围
"match_all": {}
},
"aggs": { //
"brand": { // 聚合名称,自定义
"terms": { // 聚合类型,terms,按照字段值分组
"field": "brand", ////聚合字段,品牌字段
"size": 10, // 希望获取的聚合结果数量
"order": {
"_count": "desc" // 聚合桶的排序方式,按照数量降序
}
}
}
}
}案例:对酒店品牌和所在城市进行聚合查询。(对酒店品牌进行分组,统计每个品牌的数量,并按照所在城市进行分组,统计每个城市的数量)
GET /hotel/_search
{
"size": 0,
"query": {
"match_all": {}
},
"aggs": {
"brandAgg": { // 品牌聚合
"terms": {
"field": "brand", // 聚合字段
"size": 20, // 聚合桶的大小
"order": {
"_count": "desc" // 聚合桶的排序方式,按照数量降序
}
}
},
"cityAgg": { // 城市聚合
"terms": {
"field": "city",
"size": 10
}
}
}
}度量聚合
度量聚合很少单独使用,一般是和桶聚合一并结合使用
我们对酒店按照品牌分组,形成了一个个桶。现在我们需要对桶内的酒店做运算,获取每个品牌的用户评分的min、max、avg等值。
这就要用到Metric聚合了,例如stat聚合:就可以获取min、max、avg等结果。
语法:
GET /indexName/_search
{
"query": {
"match_all": {}
},
"aggs": {
"NAME": {
"TYPE": {
"FIELD": "VALUE"
},
"aggs": { // 子聚合
"SUB_NAME": {
"TYPE": { // avg, min, max, sum, stats(包括count, min, max, avg, sum)等
"FIELD": "VALUE" // 聚合字段
}
}
}
}
}
}案例:对酒店品牌进行分组,统计每个品牌的max、min、avg、sun、count值。
GET /hotel/_search
{
"size": 0,
"aggs": {
"brandAgg": {
"terms": {
"field": "brand",
"order": {
"_count": "desc"
},
"size": 20
},
"aggs": {
"score_stats": {
"stats": {
"field": "price"
}
}
}
}
}
}另外,我们还可以给聚合结果做个排序,例如按照每个桶的酒店平均分做排序:
GET /hotel/_search
{
"size": 0,
"aggs": {
"brandAgg": {
"terms": {
"field": "brand",
"order": {
"score_stats.avg": "desc" // 按照每个桶的酒店平均分做排序
},
"size": 20
},
"aggs": {
"score_stats": {
"stats": {
"field": "price"
}
}
}
}
}
}管道聚合
管道聚合是一种特殊的聚合,它可以将多个聚合的结果作为输入,进行更复杂的聚合操作。